The combination of hosted computing and data storage in the Internet cloud has long been filled with compelling promises while bearing little fruit for IT practitioners. But after several years of stalled attempts, hosted computing and storage is finally hitting the market again in a big way.
The past year has seen a constant stream of new cloud-based service vendors and solutions, a lot of talk about out-of-the-box Web service-enabled storage from major vendors, and a seemingly constant series of mergers and acquisitions around service providers such as Mozy and Arsenal Digital. Meanwhile, nearly every cloud-based service provider is experiencing significant growth in consumer, SMB, and even enterprise markets.
Skeptical IT managers may think they’ve seen this show before — storage as a service has been marched on parade as the “next big thing” at least three times before. So why is this time different? The answer is simple: while the economics have always been compelling, this time around sophisticated applications and enormous sets of data are already in the cloud, and end-user access is more ubiquitous and reliable.
A variety of companies have developed very rich applications that have demonstrated to users the potential power of the cloud. Computing and storage in the cloud have become an ideal platform for developing sophisticated, economical and flexible services. Cloud-based technology is here to stay, will rapidly become pervasive, and will change the way you’re doing business.
Cloud-based storage has evolved from continuing attempts to de-couple storage from applications so that each resource can be optimally scaled and managed.
More importantly, storage in the cloud, which is a fundamental building block for cloud-based computing, is changing. Storage in the cloud, which the Taneja Group refers to as cloud-based storage, or CBS, has evolved into the second generation. CBS requires more than just block or file storage with a few extra services. Cloud-based storage delivers capabilities that will change how users manage storage. Whether you’re a customer or a service provider, cloud-based storage will set new precedents for storage economics and how storage is used.
What Is It?
Simply put, storage in the cloud de-couples storage and applications so that access to either can be more flexible, and data storage and applications can easily scale in response to changing user demands. In a Web-centric world, where large service providers host storage and computing, and customers buy storage and computing on a pay-per-use basis, this makes the IT infrastructure elastic and cost-optimized.
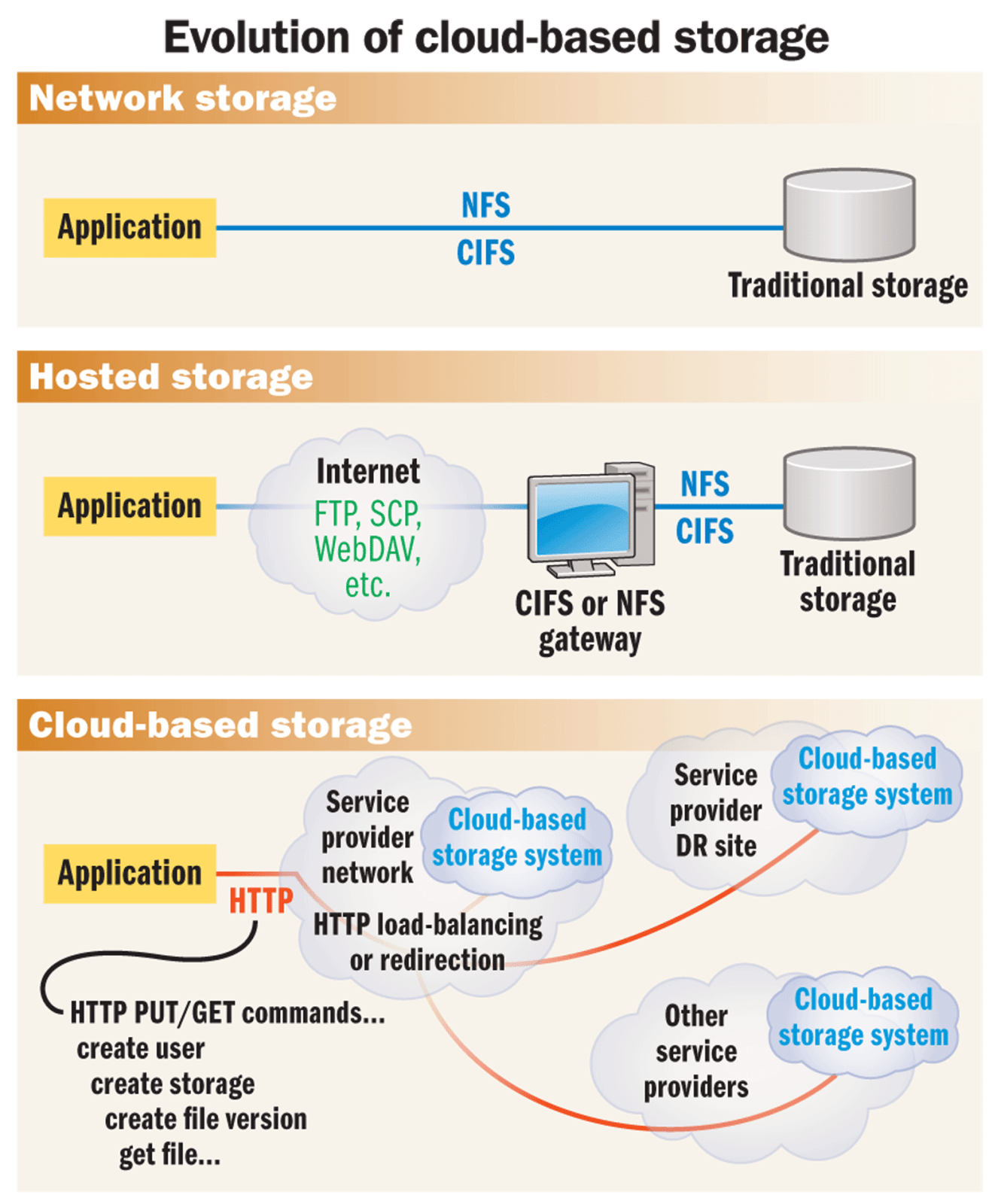
The industry has long been struggling with de-coupling applications from data so that each can be more flexibly managed, moved, and scaled. NFS and CIFS were among the earliest ways of de-coupling applications and storage so that each could be scaled and managed more effectively. But these protocols are complex and remain restricted to the data center where resources can be expensive and difficult to scale.
The next evolution of de-coupling was to host application and data components with service providers across the Web. Unfortunately, this generation of storage was often mired in the restricted scalability and complex access of traditional remote access protocols (FTP, WebDAV) and traditional storage (file and/or block).
The storage industry has realized the potential flexibility that can be enabled by storing data in the cloud, and several vendors are beginning to march into this space with a new generation of cloud-based storage.
Cloud-based technology wraps traditional IT applications and infrastructure in new, simplified APIs and access semantics. APIs, or sets of application and/or storage commands, are served up as self-contained, discoverable Web services that are accessed via HTTP or other protocols and integrated into lightweight, easy to develop, distributed applications.
This allows users to put less effort into developing complex application sub-routines, and instead better serve their businesses with combinations of already available and reusable Web services and data. In turn, the increased independence of these services allows each component to scale up and down in performance as end-user demands change. When distributed onto the enormous data centers of one or multiple service providers, this makes the infrastructure truly elastic.
Cloud-based storage is the next generation of hosted storage and represents a new paradigm in storage and data access and management whereby users can integrate hosted, location-abstracted data storage into applications and infrastructure in unique ways. CBS will serve as the foundation for elastic computing, where economical, highly manageable and easily integrated computing resources dynamically scale and change according to business demands. Cloud-based storage will
–Allow users to integrate and access storage and data in new ways, usually through Web services APIs. In turn, complex storage interactions and data access will be simplified and easily integrated into business processes and applications;
–Serve up storage and data that is location-abstracted, so that requests can be transparently redirected across locations to improve availability and enable scalability by distributing requests across multiple or larger systems as user demands change;
–Include simplified, self-service storage management capabilities (provisioning, service-level tiering, data protection, etc.) that can be easily integrated with other applications or business logic; and
–Be innovative in data organization and management so that data can be easily stored, shared, and managed in a simplified manner compared to traditional storage.
For IT managers, an API-enabled storage cloud may lay a foundation for building workflows to provision, monitor, scale, or tear down complete storage environments, including VMware server images, applications, and databases. IT managers today are using this approach to acquire storage in the cloud, rapidly provision new sets of servers, populate databases with replicated subsets of information, and fire up applications, Web servers, and database servers as user demands increase. Then, just as rapidly, these organizations turn off these new servers when user demands subside. Meanwhile, users and IT managers never think twice about where each component of the infrastructure resides, and every HTTP-carried transaction is transparently optimized and transported between different locations across the cloud.
This article focuses on file storage, which we believe will be at the heart of abstracting data storage from applications. Block storage will also have a role in the cloud, but this role may be restricted to supporting hosted virtual servers and data centers. We expect block-based storage vendors to support automation over Web services frameworks, provide richer quality of service capabilities, and deeper visibility to meet the requirements of hosted virtual infrastructures, but this infrastructure will remain tied to location and remain a disdifferent product than cloud-based storage. Meanwhile, hosted virtual infrastructures may also make use of file storage by turning to NFS-based virtual image storage.
Why Store In The Cloud?
Economies of scale allow service providers to deliver cloud-based storage at extremely low price points compared to that of a traditional infrastructure. But cloud-based computing and storage go far beyond this benefit by extending storage capabilities.
For IT customers, cloud-based storage is more distributable, scalable, accessible, and manageable than a traditional storage infrastructure. Once the locality of data becomes irrelevant, users can integrate data from anywhere. And when the location of data is no longer important, it is easy to scale performance by distributing or moving data across any system according to demand. In turn, this can eliminate disruptive data migrations or service events. Finally, since cloud-based storage is often acquired on a pay-per-use basis and is simplified in management and organization, administration is extremely low. Moreover, users can roll their own processes into lightweight Web applications to automate storage and data management.
A storage cloud can make an organization’s IT infrastructure more versatile. APIs can be wrapped with lightweight Web logic for data archiving, where users can request space, have it automatically provisioned within policy, and self-manage archiving and access to data. And managers can build business logic to automatically provision new storage, duplicate virtual guest disk images, start up a virtual environment for periodic batch processes, and tear it down when finished. Users could also integrate enterprise applications with potentially rich metadata in cloud-based storage in order to automatically classify, move, or secure data according to contents and file characteristics.
Let’s look at an example of what cloud-computing architectures, supported by cloud-based storage, look like.
Scalable Applications
For some time, the industry has tackled sticky issues surrounding how to scale front-end application and Web servers, while never coming up with better approaches to database scalability than limited scale-up to larger multi-processor servers. But in the last two years, database architectures have rapidly moved in the direction of pseudo scale-out through data partitioning and replication. For example, large-scale order entry systems may partition data into different databases by customer, or even business process, and use multiple database servers (dozens or hundreds) to scale. Data that is common to each customer is replicated into every database, and complete sets of data for reporting or analytics can be consolidated into a central repository. If a customer accesses this type of hosted application with thousands of extra users, then there is zero impact on other users and, more importantly, the subset of data and servers for that particular customer can be more easily scaled. Other predictable or unpredictable demands — data reporting and analysis, monthly batch processing, etc. — can also be handled easily.
By changing the granularity of data partitioning, it is possible to make architectures scale to support vast numbers of customers through the addition of more servers, and that is where the value of cloud-based storage and computing comes in. With CBS behind our example application architecture, businesses have begun to encapsulate each component of the application — front-end application servers as well as business logic and database servers — in different virtualized servers or applications so that they can protect, duplicate, and manage those servers with CBS tools. These companies create groups of servers in a given environment, and use automation toolsets to allocate storage space, snapshot and duplicate servers, and start up, shut down, or re-arrange the servers behind their application, based on demand and application performance.
As such an environment is deployed, it either starts up with an existing set of data or immediately replicates data from other databases and builds an entire new application environment for a new customer or process. A failure may trigger either a complete restart or an entire movement of the environment to another location. Excess demand may trigger further partitioning of data into more databases and the launch of more application servers.
With the help of solution vendors such as DataSynapse or 3tera, which specialize in the packaging and management of entire environments, some of the largest applications can handle enormous, unpredictable increases in customers without a hiccup, while optimizing costs by rapidly shutting down servers when they are not required. One vendor in this space –- Surgient — provides a management solution that wraps the virtual infrastructure in an HTTP-accessible Web service API for manipulating nearly any aspect of provisioning, snapshotting, duplicating, and scheduling virtual guests.
Conclusion
Cloud-based storage will create enormous change in the IT infrastructure. As users begin to experiment with cloud-based solutions, the technology will create a ripple effect throughout the storage industry, with several impacts:
–Users will expect cheaper storage, as user self-service makes storage in the cloud less expensive to deliver;
–Users will expect more responsive and scalable storage, because hosted providers can respond and scale on demand; and
–Users will expect to access and manage their data in ways that were not possible before.
Vendors such as Caringo, EMC, Ibrix, Xiotech, and others are racing to provide a storage services layer or APIs that will underpin the next generation of cloud-based storage. These vendors are developing cloud-based storage infrastructures that will go well beyond the limitations of first generation products that tried to provide basic FTP- and WebDAV-type access. Next-generation solutions will provide services on top of true Web services architectures. Moreover, these next-generation solutions will provide secure partitioning, data organization, and user management services.
Parts 2 and 3 of this series will examine what end users and service providers should look for when evaluating cloud-based storage solutions.

