The ever growing amounts of data being created and stored is the cause of many of the data and storage management challenges facing enterprises large and small. Additionally, the increasingly global nature of the markets and the economy is forcing businesses to place greater demands on the support infrastructure.
In other words, IT managers are asked to do more, store more, and make data more available with fewer resources. Clustering technologies can play a role in delivering greater scalability, manageability, availability, and reliability.
Recently, there has been increased hype around cloud computing and cloud storage; however, because the term “cloud” is currently the most over-used word in IT, many users do not understand what these terms mean. The promises of cloud storage are efficiency, capacity utilization, scalability, manageability, and availability.
Cloud storage is a concept for an infrastructure that is flexible, scalable, and serviceable. It is the ability to deliver storage as a service to customers internal to the enterprise or to subscribers. Regardless who your clients are, cloud storage infrastructure must achieve high levels of resource utilization for it to be cost effective, dynamic management to support both ever-changing customer needs and reliability and availability of data stored in the cloud. To achieve this goal, storage cloud architects look to technologies that enable the building and support of such an infrastructure. This is where cloud storage and clustered storage meet.
Clusters And Clouds
Clustered file systems, clustered object-based storage systems, and redundant block-based storage systems contribute to the overall design, and are the building blocks that make up a storage cloud. These technologies make it possible to provision and reclaim storage capacity seamlessly, to service and manage large pools of storage with few administrative resources, and to assure data availability and system reliability through distribution of risk across multiple components making up a cluster and across multiple storage clouds.
Though clustering has existed in other areas of the data center for a number of years, it is a paradigm shift for most storage managers. A storage manager seeking a way to improve efficiencies of the assets, and decrease costs without impacting the business, would benefit from the evaluation and adoption of clustered storage architectures. But before jumping in, make sure you understand cluster technology in all its variations.
There are three main categories of storage: file-based, object-based, and block-based. Even though these are three distinct areas of storage, they are not completely isolated from each other. File-based storage accessed via NFS can use either a block- or object-based storage system, depending on the use case. Object-based storage uses block devices, such as disk drives, and can take advantage of block-based storage system functionality, such as RAID, as an added layer of protection. Block-based storage is the foundation for all other types of storage.
With all this complexity, how is clustering enabled across the landscape?
SNIA defines a cluster as a collection of systems that are interconnected for the purpose of improving reliability, availability, serviceability, load balancing and/or performance. Servers have been clustered for a long time to achieve superior uptime and performance; however, this concept has not been explored as much in the storage industry. Storage is a function that records data and supports its retrieval, which means any storage system could theoreti- cally be clustered. To set the scene, storage can be file-, object-, or block- based. Opportunities for clustering exist at a number of places along the storage stack.
File-Based Clusters
File-based storage systems are typically either a file system accessed with the help of client software or via standard network protocols, such as NFS or CIFS. A file system is the structure by which data is written to raw devices. All data stored in a file-based storage system is seen as files. Traditional file systems that come with an OS allow one-to-one access, meaning only those raw devices associated with the specific instance of the file system can be accessed through that file system. This presents some limitations, which are being addressed in a clustered environment.
A storage file system that can be concurrently accessed for reading and writing by multiple computers is often referred to as a clustered file system. It is also referred to as a shared-disk file system where multiple computers running a file system can share access to an object- or block-based storage system. The sharing or accessing of storage resources varies across file system architectures.
In some scenarios, there is a management node that stores all location information and lets the client know which node owns the desired file. In another scenario, the request for a file can be presented to any node in the cluster, and if that file is owned by a different node, the node receiving the request can retrieve the requested file via the back-end network that connects all the nodes in the cluster.
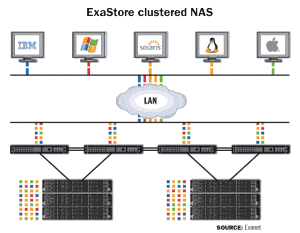 Exanet’s ExaStore Clustered NAS is based on a distributed file system that creates a single view of data in clustered nodes.
Exanet’s ExaStore Clustered NAS is based on a distributed file system that creates a single view of data in clustered nodes.
There are a number of other architectures—parallel, federated, distributed, SAN, etc.—but at a high level, the concepts are similar.
Clustering at the file-system level has been adopted in the high performance computing (HPC) space for some time. Having multiple servers running a single file system allows concurrent access of a given share or file, thus improving performance. Performance has been the traditional driver for the adoption of clustered file system technologies, but capacity scalability has more recently evolved as another use case.
As organizations seek to simplify scala- bility, management, and availability of file-based systems, clustered architectures are becoming more appealing.
Last spring at Storage Networking World, a storage manager from a large enterprise shared with me some of his challenges around managing file-based storage systems. His main challenge was load balancing users across multiple NAS appliances, which consumed too much of his time. Some users created more data then others, resulting in some appliances running hot while others remained mostly idle.
Clustering all appliances under one file system across a cluster of servers could facilitate load balancing of performance and capacity consumption. It would also improve the utilization of assets by allowing him to add performance and capacity separately and incrementally as a need arose.
The scalability of a file system depends on addressable capacity and the number of files it can handle.
Since clustering requires at least two systems, each being available in case the other fails in order to take over the work load, then clustered file systems are inherently available. This also plays to reliability, since failures occurring at the server node level, or in some cases even at the storage level, are mitigated by architectures that distribute the risk across the entire cluster. Clustered, file-based storage systems have the advantage in the usability arena by making upgrades, refreshes, hardware swaps, and maintenance available without any disruption to end users. Files can be migrated from the node to be decommissioned to the remaining nodes, enabling seamless upgrades, hardware swaps, and maintenance.
Object-Based Clustering
Object-based storage systems deal with objects that are a file or a portion of a file. Metadata as well as additional administrator-defined object attributes are placed with the object. Object-based storage systems can be accessed via standard protocols, such as HTTP or through proprietary APIs. Object-based storage systems are not file systems, although in some cases they do deal with files as objects.
Object-based storage systems are often front-ended by file systems that provide the structure to which users are accustomed. Another way to think of object-based storage is if a file system is split into two functions— user interface and storage manager. The object-based storage system would take on the role of a storage manager; the user interface would require a file system supporting NFS, CIFS, or other standard network protocols.
Clustered object-based systems are highly available, reliable, and serviceable. They are also scalable because the location of the file object, as well as a lot of other information about the file, are stored with the object itself, eliminating the addressable ca- pacity limitations of many file systems. Scaling an object-based cluster is simple; add more storage nodes to the cluster and spread the objects across all available devices, thus incorporating new hardware and extending availability.
Multiple copies of an object can be distributed across multiple nodes for added availability and reliability. It can also add to the performance of the cluster by creating multiple locations from which an object can be accessed in parallel. This protects against drive or node failure, though it doesn’t preclude the use of RAID.
Object-based storage delivers most of its value in a tiered infrastructure where data must be retained for an extended period or must be retained immutable for a specific period of time. When placed behind a file system (clustered or not), it has the potential to eliminate any scalability, availability, or distribution of data limitations that might otherwise exist.
The most common use case for object-based storage is in the archiving of data. Whether it is active archiving, content depots, or compliance-related archiving, object-based storage delivers scalability, extensible attributes that add intelligence to the repository for easier classification and search, and the immutability of the file object—which is critical in many compliance environments.
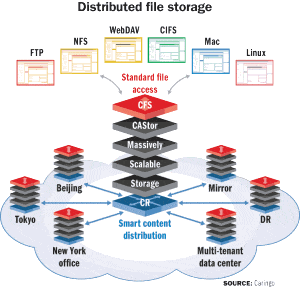
Caringo’s CAStor is a content-addressed storage (CAS) system based on a parallel storage cluster architecture and the Zero File System.
In some object-based storage clusters, performance is scalable with the addition of each node or faster processors.
Finally, object-based storage clusters are simple to service; nodes in a cluster can be added, removed, or serviced with zero down time. When a node is being removed, objects stored on it are moved to other nodes in the cluster, allowing a simple shut down. The same methodology can be used when performing upgrades that may cause disruption to operations.
Block-Based Clustering
Block-based storage systems handle ones and zeros. Where file- or object-based systems may have content awareness, block-based devices do not. Block-based storage systems traditionally have used SCSI to communicate with the server. In a networked storage configuration, storage is typically accessed via Fibre Channel, iSCSI, or InfiniBand.
Clustering of controllers for availability has been available for some time, but clustering of storage systems is not as simple as other forms of clustering. The clustering of block-based storage can be achieved using multiple storage arrays, network or path storage virtualization, and multi-pathing software. Combining two arrays behind a clustered set of path virtualization appliances where data is written to both arrays simultaneously creates a clustered environment. Additionally, multi-pathing software allows the server to be redirected if one path, virtualization node, or array fails.
Though clustering of storage systems creates the most available architecture, it has not been adopted due to the costs and complexity involved. There have been some breakthroughs in technology developments that enable more sophisticated clustering capabilities for block-based storage, but they are not currently commercially available.
Block-based storage, clustered or not, can serve as a back end to a clustered or stand-alone file system or application. Locating two arrays in separate facilities, within a distance supported by Fibre Channel for synchronicity, may add another layer of reliability where the second site can be utilized for R&D, testing, and disaster recovery, making the costs of deploying such architectures more palatable.
Unlike in clustered file- and object-based storage systems, achieving clustering in block-based storage architectures does not de- liver as much of the serviceability, load balancing, or utilization advantages. Though there is greater reliability since a failed sys- tem can fail over to the active system, there is no added I/O performance. Additionally, having data mirrored across two storage systems significantly increases the overall cost.
Clustered storage, whatever form it takes, is designed to deliver higher utilization of existing resources, flexibility in scalability, reliability and availability and—most importantly—serviceability. Not all clusters are made the same, and it is important to understand your application and environment requirements before evaluating solutions.
Whether a clustered storage solution is the right approach for you now, the architecture is here to stay and will play an increasingly important role in cloud-based storage as well as environments where storage efficiency is critical.