Data reduction, or capacity optimization, techniques such as data de-duplication and compression have become common, and well-proven, in secondary storage applications such as virtual tape libraries (VTLs), backup and archiving. And the same benefits – reduced costs (or at least procurement deferrals) and energy savings — are now available for primary storage devices; most notably, for NAS servers.
But before you start evaluating the options, it’s important to note the differences between primary and secondary storage requirements in the context of data reduction. The main difference is in performance requirements.
“The key difference between PSO [primary storage optimization] and SSO [secondary storage optimization] is in access latency requirements,” says Eric Burgener, formerly a senior analyst and consultant with the Taneja Group research and consulting firm. “Access latencies for primary storage are generally much more stringent than for secondary storage.” (For an in-depth discussion of this topic, see Burgener’s article, “Primary storage optimization moves forward” at infostor.com.)
Storage optimization processing introduces latency, although various implementations have minimized – or eliminated — the performance impact.
“It’s also important to note that there’s a lot less data redundancy in primary storage compared to secondary storage, so you’ll typically see much lower compression ratios on primary storage,” says Burgener.
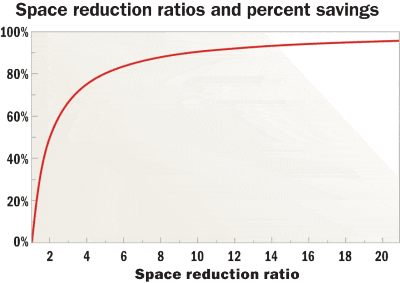
However, he says that a handful of vendors are addressing the performance requirements associated with data compression and de-duplication on primary storage, and that users should understand that three’s not a huge difference between, say, an 8:1 data-reduction ratio and a 20:1 ratio.
Data reduction on secondary storage can result in capacity optimization ratios of 20:1 or greater, whereas data reduction on primary storage will typically result in capacity reduction ratios in the single digits (although ratios vary widely depending on vendor implementation and the type of data). However, because the reduced capacity is on expensive primary storage devices, even data-reduction ratios of, say, 3:1 can result in significant cost savings; for example, ratios of only 2:1 or 3:1 can reduce capacity by 50% or 66%, respectively.
(For an in-depth look at the issue of de-duplication ratios, see “Understanding data de-duplication ratios” at infostor.com.)
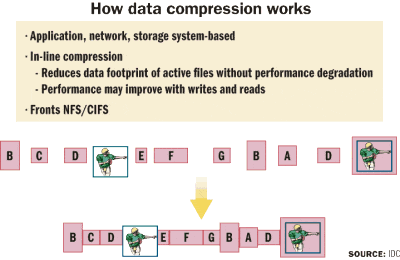
If you compare the architectural approaches that vendors are taking for data reduction on primary storage, it looks similar to the distinctions between the various approaches to data reduction for secondary storage. For example, some vendors use in-line data reduction (performing capacity optimization before data is written to disk, sometimes in real time), while others use a post-processing (i.e., after data is stored on disk) approach.
Burgener says that, in general, in-line approaches require less overall raw storage capacity, but processing speed may be an issue because of the possibility that application performance may be negatively impacted. Post-processing approaches typically do not introduce additional latency that may impact application performance, but they do require more storage capacity, depending on how quickly the data is processed into capacity-optimized form.
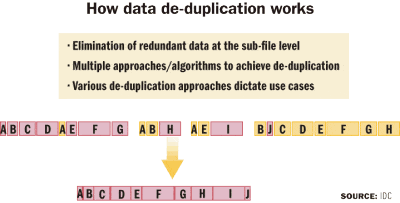
“The advantages and disadvantages of in-line vs. post-process capacity optimization depend on what technique you’re using and what the impact, if any, is on read/write performance and additional capacity requirements,” says Noemi Greyzdorf, research manager, storage software, at IDC.
In addition, some vendors use “generic” algorithms (where the same algorithms are used on all data types), while one vendor — Ocarina Networks — uses “content-aware” algorithms designed for specific types of files (e.g., jpeg, tiff, etc.).
Gating factors
When data reduction first came on the scene, end users were reluctant to deploy the technology due to concerns about performance degradation (throughput and/or latency) and data availability and reliability issues. And those concerns are amplified in the context of primary storage, where performance, availability and reliability are much more critical.
However, vendors have for the most part alleviated those issues. Although data reduction techniques may introduce latency, it is usually minimized (to low milliseconds during reads) and may not be an issue for many applications. And all of the vendors have boosted their throughput speeds.
Most vendors guarantee data reliability (i.e., retrieved capacity-optimized data is exactly the same as it was in its original form) via advanced data fingerprinting and hashing algorithms, byte-level validation, checksumming, and other techniques. And data availability issues have also been addressed, in some cases by deploying data-reduction appliances in mirrored pairs.
“Many users are still trying to understand the different methods of data reduction for primary storage,” says IDC’s Greyzdorf, “and they have to be assured that they’re not going to lose data.”
For end users planning to evaluate data reduction for primary storage, the good news is that there are relatively few players in this space, and most of them offer software that allows you to get an idea of what level of capacity optimization ratios you’ll be able to achieve with your specific data sets (although analysts still recommend checking vendors’ customer references on this point).
Although it’s possible to make some apples-to-apples comparisons between the various approaches for reducing data on primary storage devices, comparisons are largely an apples-to-oranges exercise because the implementations vary widely. However, the goal is the same: to reduce/optimize capacity, which in turns leads to significant costs savings as well as a reduction in space, power and cooling requirements and costs.
Here’s a quick rundown of the key (according to analysts) players in this space, and what they see as their main differentiators.
NetApp
Perhaps the most vocal proponent of data de-duplication, NetApp can lay claim to being the leader in the data reduction market by virtue of the sheer volume of systems the company has shipped with data de-duplication functionality (implemented in a post-processing approach). The company claims to have shipped more than 37,000 systems with data de-duplication. The question, of course, is how many customers are actually using NetApp’s de-duplication functionality.
The answer, according to NetApp’s senior marketing manager for storage efficiency, Larry Freeman, is at least 15,000 systems. (NetApp tracks this via its auto-support feature.) And of those, “about 60% are de-duping at least one primary application,” Freeman estimates.
NetApp integrated data de-duplication technology into its Data ONTAP operating system, free of charge, so de-dupe runs on all of the company’s platforms (e.g., FAS, V-Series, VTLs, etc.). In addition, via the V-Series virtualization gateway, NetApp can perform data de-duplication on its competitors’ disk arrays, including EMC, Hewlett-Packard, Hitachi Data Systems and IBM arrays. (NetApp guarantees a 35% reduction of third-party disk capacity in virtual server environments.)
Like some other players in this space, NetApp focuses on virtual server environments, where de-duplication ratios can be relatively high. In fact, Freeman says that the typical capacity savings in a VMware environment is about 70%, without any performance degradation.
EMC
Earlier this year, EMC announced support for data de-duplication and compression on its Celerra NS line of NAS platforms (which also support Fibre Channel and iSCSI). Dubbed EMC Data Deduplication, the technology is integrated into the Celerra Manager software and is based on EMC’s Avamar (for de-duplication) and RecoverPoint (for compression) technologies. The data reduction functionality is available for free. (See “EMC adds de-dupe, SSDs to NAS” at infostor.com).
EMC claims that its de-duplication technology can reduce file-system capacity by as much as 50%. (One early adopter – Karlsruhe Institute of Technology in Germany – achieved a 25% reduction in the amount of its primary data.)
For virtual server environments, EMC’s data de-duplication technology can be used with the company’s VMware View, a vCenter plug-in.
More recently, EMC announced an integration partnership with Ocarina Networks.
Ocarina
In addition to EMC, Ocarina has partnership deals with vendors such as BlueArc, Hewlett-Packard, Isilon, Hitachi Data Systems and Nirvanix.
Ocarina’s key differentiator, according to CEO Murli Thirumale, is that its ECOsystem data reduction platform provides content-aware (file type-specific) optimization through specialized algorithms. ECOsystem is a post-processing (or offline or out-of-band) approach that combines object-level data de-duplication and compression. “ECO” refers to the system’s “extract-correlate-optimize” approach to capacity optimization, in which data is first extracted into its original format (and uncompressed if the data is compressed), correlated (with hashing), and optimized with algorithms matched to specific sub-files or objects. In certain environments, this approach leads to higher levels of capacity optimization, and because it’s a post-process implementation it doesn’t degrade primary application performance.
ECOsystem includes an Optimizer, which performs capacity optimization, and a ECOreader that expands files on demand.
Ocarina found early success in image-based environments (although the technology is not limited to images). Kodak, for example, uses Ocarina’s ECOsystem to manage more than 20PB of photograph images.
Storwize
Storwize was a pioneer in the market for data reduction technology for primary storage, although the company’s technology can also be applied to secondary storage. Storwize’s key differentiator is that it uses an in-line technique based on enhanced, real-time compression (without data de-duplication, although Storwize’s technology can be used in conjunction with de-duplication).
“We’re the only company providing real-time, direct random access to optimized [compressed] data,” claims Peter Smails, Storwize’s senior vice president of worldwide marketing.
Unlike post-process data reduction techniques, Storwize’s STN appliances optimize data as it’s being created for the first time, at the point of origin, by compressing data as it’s being written to disk. As such, the platform does not require any additional disk capacity (as do post-process approaches).
To boost throughput on its appliances, the company recently introduced the STN-6000i series, which provides up to 800MBps of throughput vs.600MBps in previous versions (see sidebar, “Storwize boosts performance,” page 31).
Today, Storwize’s appliance work only with CIFS/NFS filers, although the company has a block-level compression product in development.
Hifn
Hifn, which was acquired by Exar in April, takes yet another approach to data reduction. The company is targeting OEMs with cards and software that combine data de-duplication, enhanced compression and encryption). The most recent versions of the cards – the BitWackr 250 and 255 – can be plugged into any Windows server, and are expected to be priced at about $950 (see sidebar, “Hifn’s data reduction cards support Windows”).
Unlike appliance-based approaches that sit on the storage network, or post-process approaches that essentially sit behind the primary storage device, Hifn’s cards plug into servers and optimize data being written to local disk. The de-duplication takes place in the NTFS cluster.
“NTFS does the first take on de-duplication, and then our cards and software do further de-duplication and compression,” explains John Matze, vice president of storage system products at Exar.
Another differentiator is that Hifn leverages ASIC-based hardware acceleration.
Although relatively unknown, Hifn is not a newcomer to the data reduction game; it’s cards are used in most virtual tape libraries (VTLs) equipped with hardware-based compression, including VTLs from vendors such as FalconStor, IBM, Overland Storage, Sepaton, and others.
greenBytes
greenBytes is the newcomer in the data reduction market; the company was expected to go into production shipments this June.
One of the company’s differentiators is that it bundles a wide variety of technologies, including compression, sub-file-level data de-duplication, massive array of idle disk (MAID) technology, solid-state disk (SSD) drives, support for iSCSI in addition to CIFS and NFS, and n-to-n replication. In addition, greenByte’s software is based on open-source code; specifically, OpenSolaris and a modified version of the ZFS file system for increased scalability (up to hundreds of TBs without performance barriers, according CTO Bob Petrocelli).
greenByte’s appliances use an in-line data-reduction method, with write performance of up to 800MBps.
One key technology in greenByte’s approach is what the company calls ‘probabilistic constant time searching,’ in which the system can determine whether it has seen a particular chunk (block) of data before in “constant” time, regardless of how large the file system gets. The technology is implemented on SSDs The benefit, according to Petrocelli, is high-speed de-duplication that does not degrade as the data store grows. In addition, greenByte’s approach compresses before it de-duplicates data, and can reportedly support name spaces up to 2PB.
IDC’s Greyzdorf offers the following advice for users that may be considering data reduction for primary storage: “The key is to first understand what types of data you have, what the access patterns are for the data, how much active vs. static data you have, and what you’re going to do with the data – back it up, replicate it, snapshot it, etc. From there you can get a better idea of which type of capacity optimization technology will be best for your specific environment.”